After writing in Node.js for 3 years, I felt that the majority of the posts about it were lacking deeper knowledge, especially about the event loops internals, so, I decided to dig deep and give you my insights. Node.js seems like a simple beast to handle but in reality, there are a lot of layers of abstraction behind it. From one perspective, this abstraction is great, but, like everything else in software, abstraction comes at a cost.
The purpose of this post is to show you a broader picture of how the Node core handles the event loop, what it really is and how it coexists with the JS runtime.
Lets start with asking a few simple questions and then answer them with detailed examples.
- What is the event loop?
- What are the phases of the event loop?
- What are the differences between the phases of the event loop and Node.js?
- How is it implemented in practice?
- Is Node.js really single threaded?
- Why do we have a thread pool if we already have the event loop that does all the async operations?
What is the event loop?
From the Node.js website, summarized:
Node.js is an event-based platform. This means that everything that happens in Node is the reaction to an event. Abstracted away from the developer, the reactions to events are all handled by a library called libuv.
libuv is cross-platform support library which was originally written for Node.js. It is designed around the event-driven asynchronous I/O model.
libuv provides 2 mechanisms. One is a called an event loop, which runs on one thread and the other mechanism is called a thread pool.
It is important to note that the event loop and the JS runtime run on the same thread and the thread pool is initiated with 4 threads by default. Also, libuv can be used not only in Node.js, that is why I will show the differences between the event loop itself and the event loop in Node.js context.
What are the phases in libuv?
The phases of libuv are:
- update loop time - it is the starting point to know time from now on
- check loop alive - Loop is considered alive if it has active and ref’d handles, active requests or closing handles.
- Run due timers - the timers we pass to libuv, that are past the definition of now, we defined in the first phase, are getting called. The timers are held in a min heap data structure, for efficiency. If the first timer is not expired than we know that all others below it were created later in time.
- Call pending callbacks - There are cases in which the callbacks are deffered to next iteration, this is where they are called.
- Run idle handles - internal
- Run prepare handles - internal
- Poll for IO - this is where the loop handles any incoming TCP connections. The time for how long the loop is waiting in each iteration will be explained later on.
- Run check handles - All check handles are run here, for example
setImmediateif we are in the context of Node.js - Run close callbacks - all
.on('close')events are called here, if something happened we want that the timers+poll+check callbacks will complete and afterwards the close callbacks are called, for example, thesocket.destroy()in Node.js. - Repeat
The visual diagram of the phases looks like this, do not worry if you still do not get the full picture, we still have things to cover!

What are the differences between the phases of libuv and Node.js
Node.js uses all of the above mentioned phases and adds 2 more: the process.nextTick and microTaskQueue.
the differences in Node.js are:
Process.nextTick() is not technically part of the event loop. Instead, the nextTickQueue will be processed after the current operation is completed, regardless of the current phase of the event loop. Here, an operation is defined as a transition from the underlying C/C++ handler, and handling the JavaScript that needs to be executed.
Any time you call process.nextTick() in a given phase, all callbacks passed to process.nextTick() will be resolved before the event loop continues. This can create some bad situations because it allows you to “starve” your I/O by making recursive process.nextTick() calls, which prevents the event loop from reaching the poll phase.In the context of native promises, a promise callback is considered as a microtask and queued in a microtask queue which will be processed right after the next tick queue. It is also dangerous as recursive calls to promises in theory will never reach the next tick.
When the event loop enters the poll phase and there are no timers scheduled, one of two things will happen:
If the poll queue is not empty, the event loop will iterate through its queue of callbacks executing them synchronously until either the queue has been exhausted, or the system-dependent hard limit is reached.
If the poll queue is empty, one of two more things will happen:
If scripts have been scheduled by setImmediate(), the event loop will end the poll phase and continue to the check phase to execute those scheduled scripts.
If scripts have not been scheduled by setImmediate(), the event loop will wait for callbacks to be added to the queue, then execute them immediately.
Once the poll queue is empty the event loop will check for timers whose time thresholds have been reached. If one or more timers are ready, the event loop will wrap back to the timers phase to execute those timers’ callbacks
Before we continue, it is important to note that all phases we mentioned(timers, pending, poll, close) always call 1 callback which is a macro operation that is sent to JS land and afterwards the nextTickQueue + microTaskQueue are run, no matter where we are in the event loop. Each macro operation combined with the nextTickQueue and microTaskQueue is called an event loop tick.
Here is the diagram for Node.js event loop, notice there is not much difference except the 2 queues we talked about(nextTickQueue and microTaskQueue).
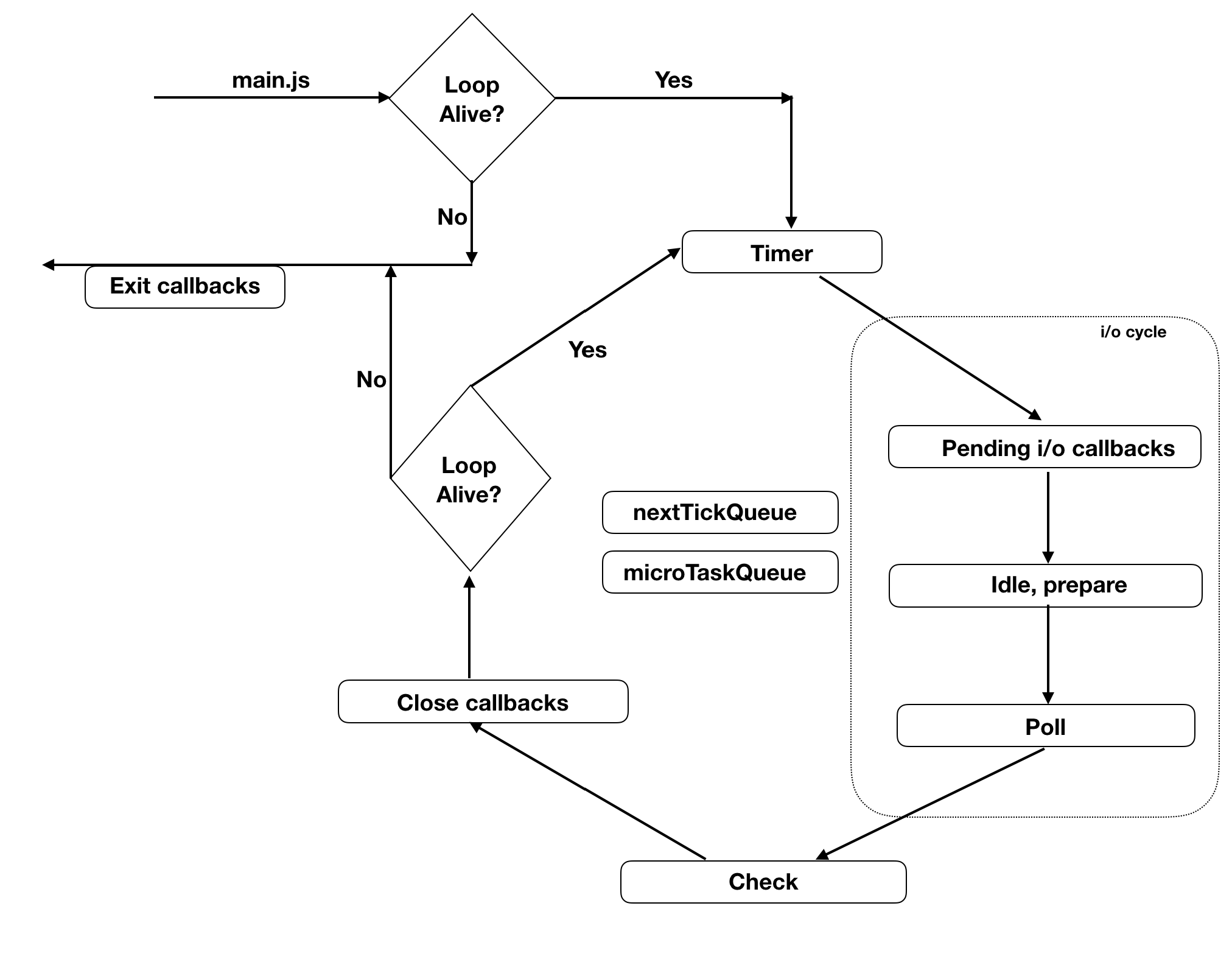
Did you notice something interesting we learned about the callback queues? Every one talks about a callback queue but in reality each phase has its own callback queue.
How is the event loop implemented in practice?
Here is the c++ code from the libuv github, I am sure you can figure the phases out by yourself and if you look carefully, you will see that the timeout for the poll phase is calculated. Also, we have a special mode of RUN_ONCE which dictates that if no callbacks were called in current poll phase, it means we have no work to do except the timers, so just update time and run timers phase before exiting.
1 | int uv_run(uv_loop_t* loop, uv_run_mode mode) { |
Let’s see how the timeout for the poll phase(waiting on TCP connections) is calculated.
To break it down for you it goes like this:
- If the stop flag is not 0, return 0
- If we dont have active handles or requests, return 0
- If the idle and pending queues are not empty return 0
- If we have closing handles return 0
- Otherwise return the next timeout from the loop
What this means is that the loop will not wait in poll phase if not neccessary, but if we have a timer, then it will wait in poll phase for the time of that timer in order to wrap to the timers phase instead of just doing meaningless iterations.
1 | int uv_backend_timeout(const uv_loop_t* loop) { |
Is Node.js single threaded?
Well, as we said previously, the event loop runs on the same thread as the JS runtime, which means, that we have one execution thread, so by definition, Node.js is single threaded.
Essentially, when the JS stack is empty of user code(all sync code we defined in our scripts), the event loop runs a tick. Important thing to note - slow sync code can halt the system to the ground at scale, due to the shared thread of the JS runtime with the event loop. More concrete, the context switch to c++ land cannot happen until the JS stack is empty.
If you try to do recursive operations in different queues(different stages of the event loop), even the setImmediate, it will always run on later ticks, remember the 1 macro per tick we talked about? This is it. But, microTaskQueue and nextTickQueue that are defined in JS land, will run recursively on the same tick, because we learned that the event loop will only run when all JS code is executed and the 2 queues above are simply javascript.
Why do we have a thread pool if we already have the event loop that does all the async operations?
This is an interesting part of Node.js land, because it is single threaded, like we already answered, but its also not! It all depends from what perspective you look at it. We do have one execution thread, but we also have the thread pool that comes along with the event loop.
Taken from the libuv website:
Whenever possible, libuv will use asynchronous interfaces provided by the OS, avoiding usage of the thread pool. The same applies to third party subsystems like databases. The event loop follows the rather usual single threaded asynchronous I/O approach: all (network) I/O is performed on non-blocking sockets which are polled using the best mechanism available on the given platform: epoll on Linux, kqueue on OSX and other BSDs, event ports on SunOS and IOCP on Windows.
What this basically means is that all operating systems have some sort of non-blocking IO handling we can leverage. We can subscribe to all events regarding new TCP connections, incoming data from TCP connection and etc. But what about crypto stuff, DNS resolving, file system operations? They are supposed to be non blocking as well, right?
Well, Not all the types of I/O can be performed using async implementations. Even on the same OS platform, there are complexities in supporting different types of I/O. Typically, network I/O can be performed in a non-blocking way using epoll, kqueue, event ports and IOCP, but the file I/O is much more complex. Certain systems, such as Linux does not support complete asynchrony for file system access. And there are limitations in file system event notifications/signaling with kqueue in MacOS.
Ok, we figured out that fs operations are problematic and must be done sync, but why DNS resolving must be sync too? To resolve DNS you must read the hosts file first on the host machine. We must use the fs for that and you get it by now…
Regarding the crypto, Cryptography on the most basic level is performing calculations, and there is no way to to calculations asynchronously on the same thread. For all the reasons above, we have a thread pool. When you send an async fs operation or an async crypto/dns resolve callbacks to the event loop, it gets picked up by the thread pool and resolved on a different thread synchronously.
Examples
Now, after we answered all the questions, lets look at some examples:
We will call the crypto.pbkdf2 async implementation.
I added a comment of how the results look in the previous example with default 4 threads that took 9xx ms completion time
UV_THREADPOOL_SIZE
1 | const { pbkdf2 } = require('crypto'); |
now set the environment variable UV_THREADPOOL_SIZE=1 and run the code again,
1 | const { pbkdf2 } = require('crypto'); |
We saw that we get sequential execution because we have only 1 thread. If you try the sync implementation we will simply block our thread, but the thread pool allows us to do all the non trivial crypto work on another thread and keep our business rolling! Isn’t that cool?
Timers
Before we start, important note, if we set setTimeout to 0, it will be 1ms.
Who will execute first? According to what we saw, it will be setImmediate because the timer has not expired yet, but try and run it several times:
1 | setTimeout(()=>console.log('setTimeout'),0) |
First time:
1 | setImmediate |
Second time:
1 | setTimeout |
The interesting part here is that we know that when the event loop runs, it checks if the timer expired, which in our case is 1ms, which is a long time for a cpu, and the setImmediate will run only on next tick after we defined it and only after poll phase!. If the timer expired on start of next tick it will be called first, if not, the setImmediate will be called first and setTimeout afterwards.
Timers + IO
Now, lets add an IO cycle
1 | const fs = require('fs') |
The fs sends the readFile to our thread pool, when the operation finishes in poll phase, it registers the setTimeout and setImmediate and as we saw, the check phase always comes after the poll phase, so our setImmediate is guaranteed to execute first.
Recursion + Timers
Recursive operations in the event loop:
take this example:
1 | const express = require('express') |
Will our web server answer our requests?
Remember we said that recursive operations are dangerous on microTaskQueue and nextTickQueue in JS land? Well, thats true, which means, that a recursive call to setImmediate will not be immediate(1 macro per tick, remember?), but split to next tick after each invocation and that means that we pass iterations through poll phase which is responsible for our IO. To answer the question - Yes, we will answer the web requests!
Promise.resolve
Now, lets see with Promise.resolve().then(compute)
1 | const express = require('express') |
The native implementation of promises work with the microTaskQueue, which will run in recursion indefinitely and our web server will never answer!
Fun fact - With native promises we could implement long running promises that do recursions, and would never continue to next ticks - so fs operations and other network IO and phases from c++ land will never get execution time! For these reasons, Bluebird and other promise libraries implemented the resolve and reject to be in setImmediate which will never starve the IO!
The process.nextTick should be obvious by now.
Promise.resolve + nextTick + Timers
Last one before we wrap up:
1 | Promise.resolve().then(() => console.log('promise1 resolved')); |
Do not be startled! Lets do what we always do in software engineering - break it down
- Promise.resolve - native implementation and on js land, it will run last after
nextTickQueue - setImmediate runs after poll phase
- setTimeout runs on timers phase
- process.nextTick must be exhausted before continuing to next tick
Now, nextTick is run on current tick and must be exhausted like we said, so it has to go first, because it runs on JS land regardless of where we are on the event loop!
After the nextTick we have the microTaskQueue which like we said previously, is run last after nextTickQueue so it runs.
We have a process.nextTick inside the callback of a micro tick. That one we did not cover on purpose! What do you think will happen? Like we said, the nextTickQueue must be exhasted on each iteration, and we added a callback to the queue, so it wraps back to nextTickQueue and runs the callbacks again.
After all those steps we finally can start a new tick and by this time our timer has elapsed, so our setTimeout gets executed, our setImmediate is last and the result is:
1 | next tick1 |
Summary
We started by asking a few basic questions in Node.js, like: how does its internals look like and how does it operate? Later on, we tried to answer each of those questions as deep as possible. We learned that after all the abstractions, it is a (not so simple) while loop which enables us to build advanced systems and build web servers without worrying about concurrency control or multi threading. Finally, we saw some examples that seem trivial at first, but after our dive to Node core, we were able to answer them.